Did you ever come across an error like below ever?
/usr/bin/docker-current: Error response from daemon: devmapper: Thin Pool has 1026 free data blocks which is less than minimum required 163840 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior.
Then you are looking at the right place. Few things that I have to point out before telling you how to resolve this and how to go with your implementation to begin with:
- If you are seeing this on your local, don’t stress, re-install docker and everything should be good. (Remember: This will remove all existing images / containers / volumes). Basically it’s a clear slate for you to do a fresh start 🙂
- If you are seeing this in your dev environment then I guess you can just follow 1 and no one cares
- But if you see this any where else like, your test / integration / staging / production environments then be sure that you took a considerably big risk and didn’t follow docker documentation to the dot.
But it is always better to understand this as a design.
Docker needs some storage to store all that you are creating with-in it’s realm. Like when you create a container it will use some storage from this space and create a container for you… or when you pull an image… it should be able to store this somewhere, correct? These are called storage drivers.
Now, there are different storage drivers for different version on different operating systems. Believe it or not, every thing is very very well documented. You can find all that information for Docker CE, here and for Docker EE, here. And the underlying file system if required for each of these storage drivers, here.
Out of all these, overlay2 and devicemapper will suite most of the use-cases we generally find. Above error is when you are using devicemapper. Most commonly with loopback-device. There are ways to get out of issues, but I was not able to recover lost space even after cleaning up the whole device.
Loopback-device will use your existing filesystem, ext3 or ext4 and devicemapper being efficient on block storage will have obvious performance hits. To avoid this completely start using direct-lvm mode where you mount a 200G (or some according to your load) volume on your Server and use according to the load and if you ever run out of space then add another volume and extend your logical volume or lvm.
So let’s take an example, I have a CentOS server on my Oracle VirtualBox. Now I create a new Volume on OVB and attach it to my CentOS server:
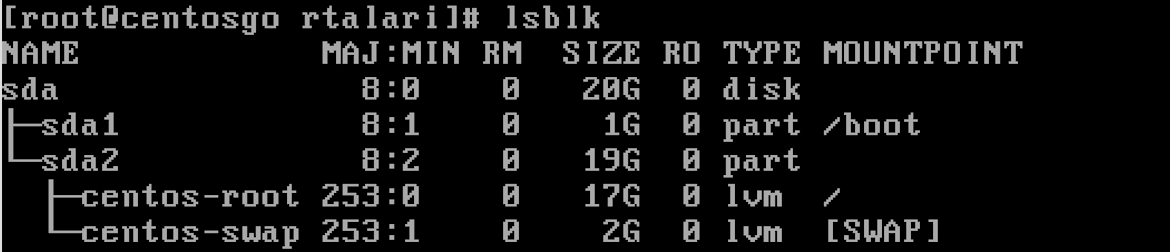
Before:
After:
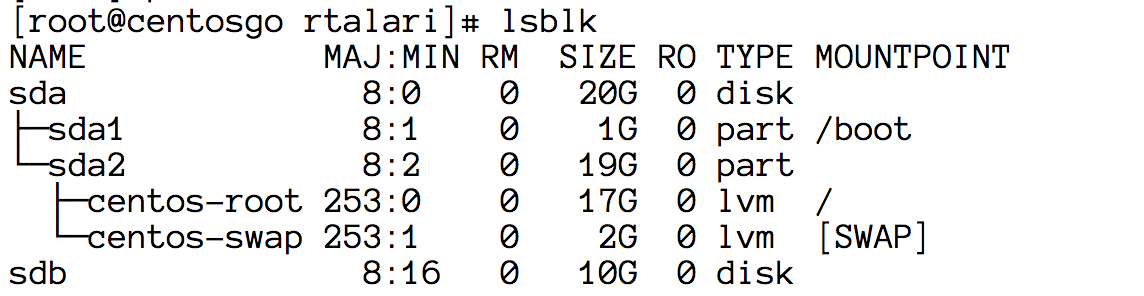
Now you see a 10G sdb in there. Create a Physical Volume
pvcreate /dev/sdb
Create a Volume Group called docker
vgcreate docker /dev/sdb
Now create a Logical Volume (lvm) [instead of thinpool you can give any name of your choice, like thinp / tpool / thpool]
lvcreate --wipesignatures y -n thinpool docker -l 50%VG
This will create a logical volume thinpool with 50% of space from your VG which is 10G. So it will allocate 5G for this thinpool volume. Now you will see a link (docker-thinpool) in your /dev/mapper which will be linking to a block under /dev.
Now create some space for metadata
lvcreate --wipesignatures y -n thinpoolmeta docker -l 1%VG
This will create another directory docker-thinpoolmeta as well in your /dev/mapper. Convert these to a thinpool using lvconvert
lvconvert -y --zero n -c 512K --thinpool docker/thinpool --poolmetadata docker/thinpoolmetaCongratulations, you now have your thinpool with configured with direct-lvm mode. Just one small thing that is still left to do is to make sure your thinpool can scale automatically. Like if we fill it up by 80% (by pulling images, creating containers etc) then instead of giving us an error it will extends from 50% which 5 GB by 20% and will become 6 GB. Put below configuration in /etc/lvm/profile/docker-thinpool.profile [VGName-ThinpoolName.profile].
activation {
thin_pool_autoextend_threshold=80
thin_pool_autoextend_percent=20
}Now update your LV with this profile with lvchange command
lvchange --metadataprofile docker-thinpool docker/thinpool
Now add a monitor that will trigger auto extension of your thinkpool.
lvs -o+seg_monitorNow create a file daemon.json in /etc/docker and below content
{
"storage-driver": "devicemapper",
"storage-opts": [
"dm.thinpooldev=/dev/mapper/docker-thinpool",
"dm.use_deferred_removal=true",
"dm.use_deferred_deletion=true"
]
}That’s it just start docker service and check docker info. You have now devicemapper storage driver with direct-lvm mode setup.
Now when your thinpool fills up by 70% you can setup an alert and you can either cleanup by removing unwanted artifacts that are still lingering around or add another block to the VG Group and your auto-extender will keeping extending the thinpool.
Cleaning up Unwanted artifacts on docker:
$ docker ps -aq -f status=exited | xargs docker rm $ docker ps -aq -f status=created | xargs docker rm $ docker images -q -f dangling=true | xargs docker rmi $ docker volume ls -q -f dangling=true | xargs docker volume rm
Extending a Thinpool Volume
It is just like extending any other logical volume:
- pvcreate a create a new physical volume on your new /dev/sdd
- Add this newly created volume to VG by vgextend docker /dev/sdd
That’s it your auto extend should be able to extend now.
Please note that you need to have permissions to execute all the commands that were given in this post.